


种子轮5000万好意思元,估值不到一年暴涨20倍,微软和SpaceX同期争抢收购。这家叫Inception Labs的公司,靠的不是更大的模子、更多的算力,而是一条险些无东说念主敢走的工夫道路。
事情在2026年5月13日聚积爆发。外媒同日报说念微软和马斯克旗下SpaceX都在和Inception Labs谈收购,开价跳跃10亿好意思元。两个万亿级巨头同期争抢一家职工不及百东说念主的初创公司,这种形貌在AI行业并未几见。步伐会这场争抢背后的逻辑,需要先结实Inception Labs在作念一件什么事。
把扩散模子搬进文本生成,这个念念法也曾被合计是异端
Inception Labs的故事要从独创东说念主Stefano Ermon提及。他是斯坦福大学盘算机科学教练,同期亦然扩散模子的共同发明东说念主之一。今天东说念主们用的Midjourney、Stable Diffusion、Sora,底层都跑着他参与草创的工夫框架。他对于文本扩散的论文拿过ICML 2024最好论文奖。
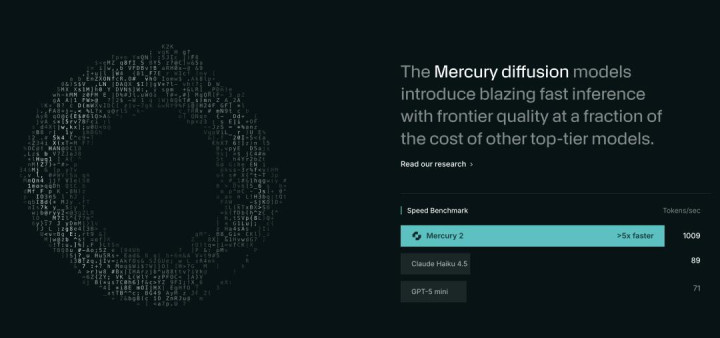
Mercury 2 模子在每秒 token 输出上比流行的小模子更快|图片开首:Inception
2024年中,Ermon从斯坦福放假,拉上了配合跳跃10年的两位老搭档,UCLA教练Aditya Grover和Cornell教练Volodymyr Kuleshov,在帕洛阿尔托创立了Inception Labs。
三个东说念主有一个其时看来颇为"离经叛说念"的中枢念念法:把扩散模子从图像生陈规模移植到文本生陈规模,从根柢上替换掉自总结架构。
这个念念法在2024年并不受待见,原因很毛糙。扩散模子在图像规模也曾被考据相配见效,但文本是闹翻的、有语义礼貌的,华游体育中国官网入口和连合的图像像素在数学性质上有内容各异。把扩散模子强行套进来,在好多东说念主看来就像是用榔头拧螺丝。
但Ermon团队合计这个贫寒不错被克服,而一朝克服,收益是结构性的。
每秒1000个token,比主流模子快了整整一个数目级
步伐会Inception Labs的工夫价值,需要先结实自总结模子有什么根人道的局限。
ChatGPT、Claude、Gemini,这些主流大模子的底层都是自总结架构。它们生成文本的现象是从左到右逐字输出,每生成一个token之前,中国官方网站必须等前边系数token都已生成。这种串行结构有一个天花板:不管芯片多快、优化多好,速率上限被串行生成这个内容锁死了。
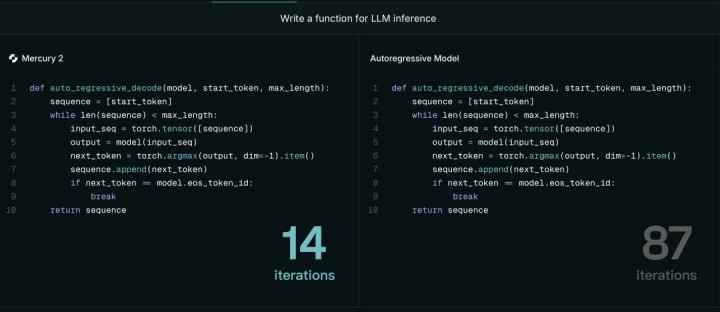
代码构建上 Mercury2 模子只用迭代 14 次,而其他模子要迭代 87 次|图片开首:Inception
开云app在线体育中国世界杯官网扩散模子的生成逻辑十足不同。它不是逐字写,而是先生成一个迟滞的合座草稿,然后通过神经汇聚反复去噪考究,在这个经由中不错同期修改多个位置的token,终了并行输出。
Ermon的原话很直白:系数现存的大语言模子都是自总结的,一个接一个从左到右生成,这相配慢,因为你必须先生成前边系数内容才智生成后头的内容。
执行后果也曾不错用数字话语。Inception Labs推出的模子眷属叫Mercury,2026年2月发布的Mercury 2经第三方评测机构Artificial Analysis测试,输出浑沌量约为每秒1000个token。手脚参照,Claude 4.5 Haiku约为每秒89个token,GPT-5 Mini约为每秒71个token。速率差距达到10到14倍。
这种速率上风在特定场景下意味着什么?对于需要及时期码补全的修复器具、需要大范围并发的企业API工作、对延伸至极敏锐的旯旮盘算场景,这不是镌脾琢肾,而是能否执行落地的门槛问题。
Andrej Karpathy在Inception发布第一个模子时就公开抒发了敬爱,他指出今天险些系数LLM在中枢建模技艺上都是"克隆体",而扩散模子有后劲展现全新的智商特征。他和吴恩达随后都以天神投资东说念主身份参与了种子轮。
当Karpathy和吴恩达同期押注,当NVIDIA、微软M12、Databricks的战投基金同期出当今投资东说念主名单上,这也曾是AI规模能集皆的最顶级背书声势了。
微软和SpaceX同期出手争抢,动机各有侧重。微软需要这项工夫来强化Azure的推理服从,在和亚马逊、谷歌的云工作竞争中取得各异化上风。SpaceX和星链则对低延伸、高并发的旯旮AI推理有锐利需求,一个速率快10倍的语言模子对其星上盘算架构具有径直价值。
自总结模子总揽AI文本生陈规模也曾快要十年。Inception Labs押注的这条路,究竟是果真的架构翻新,如故一个被过度炒作的工夫地方中国官方网站,谜底也许很快就会揭晓。

 备案号:
备案号: 